故障分析:内核参数设置不当导致数据库异常重启
更新时间: 2016-10-19 23:06
编辑手记:数据库中每一个不起眼的参数,都有其内部的原理,不可随意更改。今天分享一则因内核参数SEMOPM设置太小,加上在业务高并发时段LGWR写入太慢,系统调用失败,最终数据库异常宕机的案例。
数据库CRASH,在CRASH前,ALERT中显示如下的日志内容
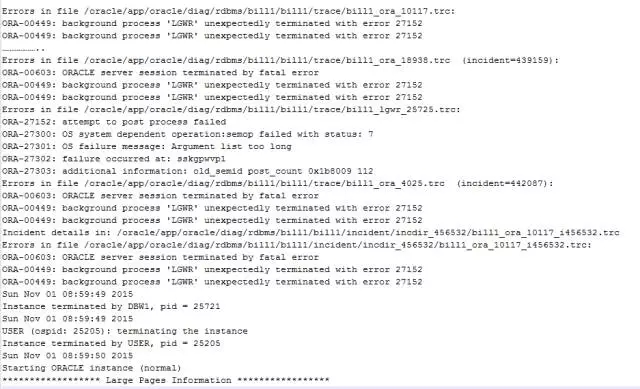
我们看到中间有27300和27301的错误。
27300:OS system dependent operation:string failed with status: string,操作系统调用失败。
1、后台日志分析
在某天 08:59:34.664000 +08:00开始,出现大量下面日志信息:

此错误是前台进程等待LGWR返回结果,但是LGWR一直没有返回,前台进程认为LGWR出现致命的错误。
在随后出现下面的日志信息:

这里显示LGWR进程在POSTPROCESS时,调用semop进程出现状态7的错误,文字描述是Argument list too long,对应的变量是E2BIG。
错误函数变量定义,manerrno:
E2BIG Argument list too long (POSIX.1)
semop错误说明
E2BIG The argument nsops is greater than SEMOPM,the maximum number of operations allowed per system call.
说明进程在system call时,如果nsops的值大于系统配置的SEMOPM时就会报E2BIG错误。
2、主机参数配置
查看系统参数配置
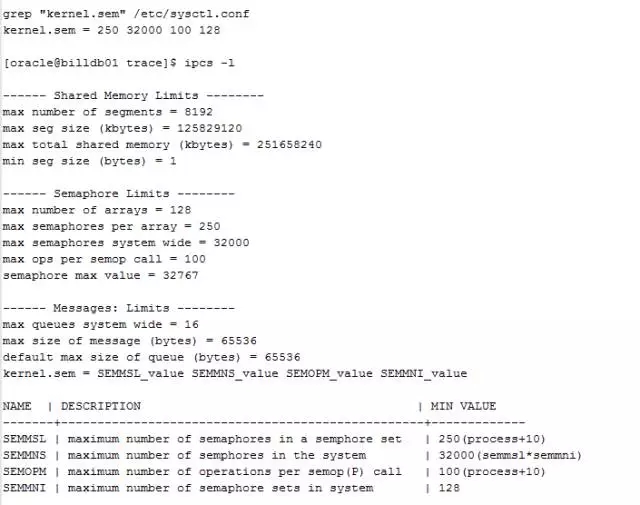
这里看到SEMOPM的值为100,在ORA-27303报错时,显示值112,大于系统配置的100的,所以LGWR一次SYSTEM CALL不能POST所有前台进程,部分前台进程认为LGWR进程出现致命错误,最后导致数据库自动重启。
3、分析SEMOPM为112原因
查询ASH数据
由于ASH最近1小时的数据都是存放在内存中,数据库CRASH时,并没有将内存中的数据写入数据文件中,所以这里不能从ASH中查询到任何的信息
查看操作系统LGWR,DIGA日志
主机上面无重启前的LGWR,DIAG日志信息。
最近数据库性能趋势
该数据库从故障前十天左右号某业务上线后,数据库每秒的REDO达到20~40M,物理IO也读达到200M/S以上,写达到100M/S,网络流量达到60M/S,IO延迟与网络延迟都很严重,所以怀疑是在高并发情况下,导致数据库日志写入慢,大量前台进程(报错时112)等待LGWR的POST信息,超过内核参数配置的100值。
修改主机kernel.sem的值,建议修改成跟模板数据库一致,修改此参数需要重启数据库。
1、 优化该数据库的SQL,减少物理读,出账结束后就开始收集优化信息。
2、 增加主机CPU资源,修改网络绑定的方式,减少网卡软中断的次数与包重传的次数。
3、考虑重启主机。
4、 继续跟开发一起分析业务,查询为什么业务执行次数与AWR中SQL统计的次数差异很大,找到日志量变换的原因。
5、 更换更好的存储,提高IO性能。



